
V předchozí části (procházení, indexování a hodnocení stránky) jsem psal o tom, jak vyhledávače posílají pavouky (Googleboty), aby procházeli a indexovali obsah vašeho webu. Pavouci prochází interní odkazy na vašich stránkách, přesouvají se ze stránky na stránku, aby objevili obsah. Existuje ale další způsob, jak pavouci mohou objevit váš obsah.
Sitemap.xml
Definice Sitemap: Mapa stránek je seznam obsahu webových stránek, který má pomoci uživatelům i vyhledávačům v navigaci na webu. Mapa stránek může být hierarchickým seznamem stránek (s odkazy) uspořádaných podle tématu, nebo dokument ve formátu XML, který usnadňuje vyhledávacím botům procházení při indexaci stránek pro vyhledávače.
Soubor (stránka) sitemap.xml je jako podpultový seznam všech adres URL na vaší stránce. Vyhledávací pavouci přistupují k souboru sitemap.xml, aby dostali přehled o všech stránkách, které na webu máte a chcete, aby byly objeveny.
Sitemap.xml je prakticky jako záloha architektury vaší stránky. Primární cestou pro zjišťování obsahu je vaše vnitřní struktura vnitřních odkazů (prolinkování), takže dbejte na to, aby vaše stránky byly vždy dobře "prostupné", stránky na sebe odkazovaly a vy jste tak usnadnili prohledávacím robotům prohledávání všech cestiček na vašem webu.
Soubor Sitemap.xml se do indexu Google posílá prostřednictvím služby Google Search Console. Kdykoli se pustíte do práce na SEO na novém webu, měli byste se přihlásit do služby Search Console a zkontrolovat, zda byl soubor Sitemap odeslán a indexován. Pokud zjistíte, že soubor Sitemap byl indexován a prohledán, ale indexovaný počet stránek je menší, než by měl být, znamená to, že něco není správně.
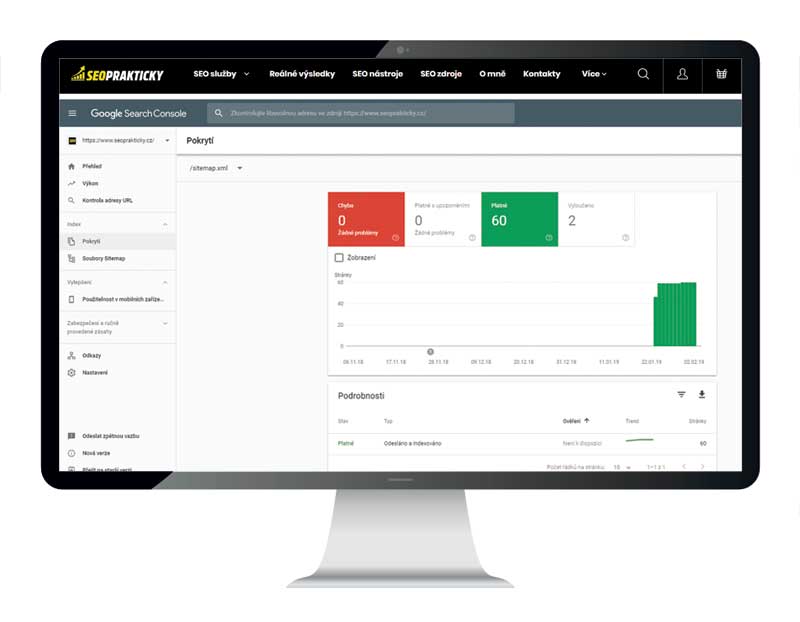
Kontrola sitemap.xml v Google Search Console
To, jak vypadá vaše sitemapa se přesvědčíte jednoduše zadáním příkazu do adresního řádku, např. https://www.seoprakticky.cz/sitemap.xml. Výpis seznamu odkazů stránek pak bude vypadat následovně.
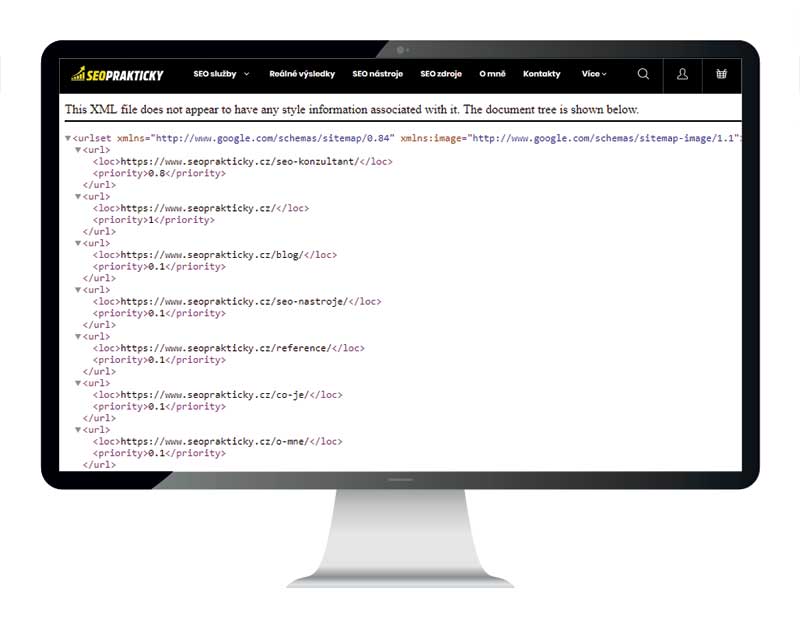
Takto vypadá, když si načtete soubor sitemap.xml.
Robots.txt
Definice Robots.txt: Standard vyloučení robotů, známý také jako protokol vyloučení robotů nebo prostě robots.txt, je standard používaný webovými stránkami pro komunikaci s webovými prohledávači a jinými webovými roboty. Standard specifikuje, jak informovat webové roboty o tom, které oblasti webu by se neměly zpracovávat nebo skenovat.
Po kontrole "podpultového" souboru obsahující seznam všech stránek na webu - Sitemap.xml, budete chtít zkontrolovat další "podpultový" soubor - robots.txt. Jedná se o textový soubor uložený v kořenovém adresáři vašeho webu (na FTP serveru - hostingu), který instruuje vyhledávače o tom, které stránky by měl a naopak neměl procházet.
Pokud nechcete, aby vyhledávače procházely stránku, můžete do souboru robots.txt vložit směrnici, která jim procházení zakáže, možná lépe řečeno jim zakáže indexaci (uložení si obsahu stránky na server).
Zatímco toto opatření může pomoci udržet konkrétní stránku mimo index Google, nezajistí to odstranění již načtené stránky, která již v indexu je. Direktivu Robots.txt nejčastěji použijete, chcete-li zablokovat stránky nebo celé části vašeho webu, např. adresář obsahující administrativní sekci webu.
Chcete-li odstranit stránku z indexu Google, budete muset tedy použít některou ze značek.
Příkaz noindex zajistí, aby se stránka nedostala do indexu Google, ale stále umožňuje pavoukům pokračovat na odkazy na stránce. Pokud použijete příkaz noindex, nofollow, stránka nebude indexována a pavouci nebudou následovat žádný odkaz na této stránce.
Pakliže se některá z vašich důležitých stránek nenachází s indexu Google, je to pravděpodobně proto, že její indexace je zakázána pomocí souboru robots.txt nebo pomocí metada robotů. Zkontrolujte tak oba, abyste se ujistili, že žádný z nich problém nezpůsobuje.
A jak si zkontrolujete soubor robots.txt? Opět do adresního řádku prohlížeče zadáte např. www.seoprakticky.cz/robots.txt
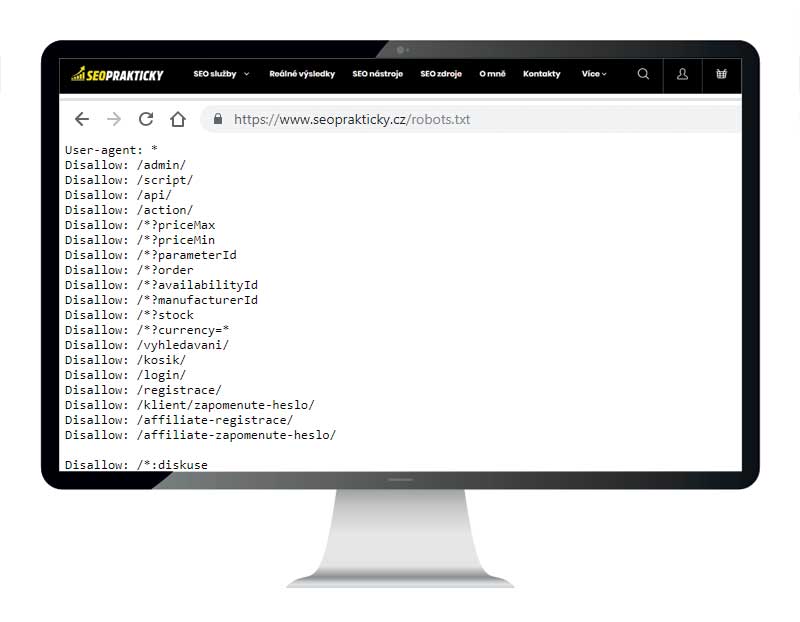
Kontrola robots.txt - zde vidíme, jaké stránky mají omezený nebo zakázaný vstup na stránky, resp. jejich indexaci.
Meta tag "robots" v kódu stránky
Instrukce botům můžete dávat i na jednotlivých stránkách přímo kódem v záhlaví HTML kódu prostřednictvím meta tagů.
Jaké jsou významy různých zápisů meta tagu "robots"
Nejobvyklejší zápis vypadá takto: <meta name="robots" content="index, follow">
Tento zápis říká robotům, že mohou stránku indexovat a přejít na všechny následující stránky (přes dostupné odkazy).
Změnou index na no-index a follow na no-follow můžete ovlivnit chování procházejícího pavouka. Jestliže nechcete, aby boti neprocházeli celý web, použijte následující kód.
<meta name="robots" content="index, nofollow">
Pavouk se bude dívat pouze na tuto stránku a dál nebude pokračovat.
<meta name="robots" content="noindex, follow">
Pavouk tuto stránku nebude přidávat do svého indexu, ale bude procházet zbývajícími stránkami na vašem webu.
<meta name="robots" content="noindex, nofollow">
Pavouk tuto stránku nezaindexuje a ani nebude pokračovat v procházení webu.
Další důležité zdroje k tématu robots.txt a sitemap.xml
- Informace o souborech robost.txt (podpora Google Search Console - CZ)
- Informace o souborech sitemap.xml (podpora Google Search Console - CZ)
- Časté dotazy ohledně robots.txt (fórum GSC - CZ)
- Nástroj pro otestování robots.txt
Další lekce v kapitole technické SEO
- Proč se zabývat technickým SEO
- HTTPS - zabezpečená komunikace
- Rychlost webu
- Robots.txt a sitemap.xml
- URL
- Duplicitní obsah a kanonické odkazování
- Strukturovaná data
- Stavové kódy 200, 301, 302, 404, 500, 503

Chcete vědět víc o SEO? Podívejte se na celý obsah SEO Akademie.